Agent team, but homemade
TL;DR. CamWatch is five repos, five Claude Code sessions. Instead of context switching, a coordinator runs them as a team: Claude’s agent teams, but every agent in its own repo. Cross-component features like multi-camera support get discussed and designed once with the coordinator, then dispatched to the agents for development.
Five repos, five sessions, one me
CamWatch, the street-watching system from the camwatch series, stopped being one repo a while ago. It is now five: a capture engine, a web app, a camera-tooling repo, a speed refiner, and a license-plate reader, plus a sixth docs repo where the system-level contracts and decisions live.
Each repo has its own Claude Code session, and that separation is worth defending. A session opened in a repo gets that repo’s CLAUDE.md (the instructions file Claude Code reads at session start), that repo’s permission settings, and a context window full of that repo and nothing else. The plate reader’s session knows its camera protocols cold; the web app’s session knows its database migrations. Neither has to page in the other’s world.
The cost surfaced the moment a feature spanned components. Multi-camera support meant a data-contract revision that every repo had to code against at once, and I became the integration layer: context switching between five sessions, carrying state from one conversation to the next, telling the web session what the engine session had just decided. Each session was excellent inside its repo; everything between repos was me.
The fix is what any growing team does: hire a manager. A coordinator session now lives in the docs repo, and it is the only session I talk to. It owns the contracts, writes the work orders, answers design questions, verifies finished work, and never touches component code. I context switch into exactly one conversation; the coordinator manages the other five.
Which left the actual problem: how do six Claude sessions talk to each other?
The native answer is almost there
Claude Code ships an experimental feature that is almost exactly this: agent teams. One session acts as the team lead, which creates the team, spawns teammates, assigns tasks, and synthesizes results. Teammates are separate Claude Code instances, each working independently in its own context window. They coordinate through a shared task list, where tasks move from pending to in progress to completed and can depend on each other, and a mailbox, the messaging system that carries messages between agents automatically. The architecture is the right long-term shape, and the vocabulary alone says its designers were solving this exact problem.
The blocker is one line in the current design: teammates run in the lead’s working directory. One teammate per repo is impossible today; per-teammate working directories (plus per-teammate CLAUDE.md and permissions) are tracked in anthropics/claude-code#23669, still open as of this writing.
The workaround for “each agent gets its own directory” is to not use teammates at all: run each implementer as a separate, full Claude Code session dispatched in its own repo. Each one keeps its own working directory, instructions, and permissions, which is exactly the isolation agent teams can’t give yet. But now nothing connects them. So the connective tissue, the lead, the task list, the mailbox, had to be made at home, out of the one substrate every session can already read and write: files.
v1: channel files and a human messenger
The first protocol was designed in a day and ran the same day. Three artifacts:
- A channel file per repo, an append-only conversation between the coordinator and that repo’s session, living in a comms folder that is deliberately not inside any git repo. One stray
git add -Ain any session must never be able to sweep half-finished chatter into a pushed commit. - A committed
HANDOVER.mdper repo: the work order, with scope and acceptance criteria. Its presence means work is pending; the implementing session deletes it in its final commit to signal done. - The docs repo as the durable record, with a promotion rule: channels are disposable scratch, and any conclusion with lasting value (a contract decision, a schema shape) gets promoted into the committed docs, with the thread noting where it went. Losing a channel file loses only chatter.
Delivery was polling. Nobody got notified of anything; each session checked its channel at natural moments, and I nudged whichever session should look next. The human was the scheduler.
It worked. v1 drove the multi-camera contract change across three repos (two of the three have since deleted their handover, v1’s done signal). But one real day of running it exposed three design flaws:
- I was the message bus. Every question sat unanswered until I noticed it and nudged the other side. The sessions were autonomous; the conversation between them was not.
- A shared channel has two writers. The protocol needed a “read the tail before appending” rule because both sides appended to the same file, and a rule you have to remember is a race you will eventually lose.
- Done was informal. Deleting a handover leaves no archive, no verification step, and no record distinguishing “the agent says it finished” from “someone checked.”
v2: what one day of bruises bought
The second protocol was designed the next day. The shared channel becomes a per-repo mailbox directory:
<comms>/<repo>/tickets/<slug>.md work orders (coordinator-owned)
<comms>/<repo>/to-agent.md inbox (coordinator writes, agent watches)
<comms>/<repo>/to-coordinator.md outbox (agent writes, coordinator watches)Three rules carry the design, each one a direct answer to a v1 flaw.
Single-writer. Every file has exactly one writer, and no session watches a file it writes. The coordinator writes tickets and the inbox; the agent writes the outbox. Append races are not forbidden, they are structurally impossible, and so are self-wake loops (you can’t be woken by your own append).
Event-driven wake. Each side holds a watch on the files the other side writes: a 26-line shell script that watches a file for growth, run under a persistent Monitor (a Claude Code tool that runs a script in the background and wakes an idle session whenever the script prints a line). Appending to a mailbox is the wake signal. An agent with nothing to do sleeps at zero cost and wakes within seconds of its inbox growing. This is the homemade rebuild of the two delivery features agent teams ships natively, automatic message delivery and idle notifications, with one honest difference: official teammates can message each other directly, while here everything routes through the coordinator. The human stops being the scheduler entirely; a half-hourly coordinator heartbeat backstops the rare dead watch, because silence is not success.
Verified close. Work orders are now tickets, the homemade shared task list: Jira-style files with a status lifecycle (open / in-progress / blocked / resolved / done) and dependencies, owned by the coordinator end to end. Where the official task list uses file locking so two teammates can’t claim the same task, here the race is removed rather than locked: only the coordinator writes tickets. The agent never edits one; it posts resolved on its outbox with evidence against the acceptance criteria, and the coordinator verifies, compiles the ticket’s full conversation from both mailboxes into the ticket file, and archives it into the docs repo. The reporter closes, not the assignee. The backlog is ls tickets/; the archive is the changelog; nothing is ever deleted.
One more mechanism rounds it out: a stop-gate, wired as a Stop hook (a script Claude Code runs whenever a session is about to go idle, which can refuse and send it back to work). An agent may not go idle past an unanswered inbox; it must post its state to its outbox first. Agent teams ships the same idea as its TeammateIdle hook; the homemade version is a comparison of two file timestamps. Sleeping is the normal, free state between wakes, but sleeping on a question is mechanically impossible.
Permissions: a hundred gates or one audited action
One thing a day of real traffic exposed was permission friction. Early on, every consequential action was gated: pushing, deploying, writing to the production database. Each gate meant the agent posting a request, the coordinator escalating, and the owner authorizing in-session. Safe, but the human is back in the loop, now as a permission clerk instead of a messenger.
The replacement: each repo session gets a scoped allowlist (a standing list of pre-approved actions): push to origin, run the package manager, and execute scripts/deploy.sh without per-action approval. Everything else on the production box stays gated. That makes the deploy script the security boundary, so it stays narrow and reviewed: pull, sync, restart only its own service, health check. The coordinator refused to close the ticket until the script also carried a branch guard, refusing to deploy anything but main. One audited action, instead of a hundred prompts asking variations of the same question.
Three days in
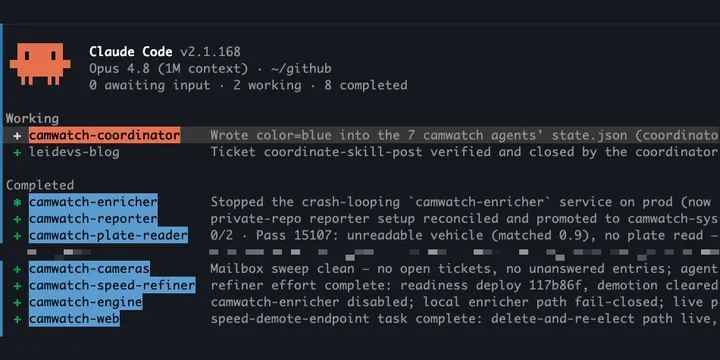
The setup is young, but the throughput is real and the files make it checkable:
- Day 1: v1 designed and running; the multi-camera contract change coordinated across three repos.
- Day 2: v2 adopted at midday, and its first effort ran the same day: a license-plate-reading pipeline, seven tickets across three repos, first assignment at 12:25pm, last ticket archived before 10pm. Ticket threads ran from 3 to 20 entries; the smallest ticket went open to verified-closed in three minutes.
- Day 3: a third effort live, instrumentation and dashboards across three services, plus the deploy-script tickets above.
And the original pain is gone: a feature that spans components is now a set of tickets and a watched mailbox, not a day of me ferrying decisions between terminals. Five implementing repos so far, and a sixth mailbox was added today: this blog. The post you are reading is a ticket. An agent session in the blog’s repo swept its mailbox, read the archived threads as source material, drafted this, and posted resolved on its outbox for the coordinator to verify. The protocol is writing its own story.
The takeaway
The team removed me as the blocker. The bottleneck was never the sessions; it was me relaying decisions between sessions that were each perfectly capable of working alone, and development moved at the speed of my context switching. With delivery on file watches and safety on scoped gates, my surface shrank to the things a human should actually be doing: high-level design, structure, and the judgment calls the docs can’t answer. A feature gets discussed once, with the coordinator; implementation belongs to the agents. One Claude session at a time already felt like a 5x force multiplier; a coordinated team of them feels like at least 10x. And the shape scales by adding a layer to the tree: I can see a future with one coordinator per project, each running its own per-component agents, and me talking only to coordinators.
Conclusion
This is a workaround with an expiry date, and that is fine. When anthropics/claude-code#23669 ships per-teammate working directories, the migration is natural because the homemade parts already have official names: the coordinator becomes the team lead, tickets become tasks on the shared task list, mailbox files become the mailbox, the watch scripts dissolve into automatic message delivery, and the stop-gate becomes a TeammateIdle hook. Until then, files are a surprisingly complete substrate for a team of agents: no framework, no server, nothing to install, and every message between sessions is a line in a file you can still read six months from now.